
Поможет ли AutoML исследователю данных или заменит его? Ч.2
Автор: Дмитрий Ходыкин, руководитель AI/ML проектов в компании ITentika
ЧАСТЬ 2
Наш опыт в построении решения AutoML
В первой части материала мы сделали обзор рынка AutoML-решений и пришли к выводу, что все они имеют достаточно высокий порог входа.
Мы задались вопросом о том, можно ли построить базовое решение (proof of concept), которое могли бы использовать представители бизнеса для проверки тех или иных гипотез на имеющихся под рукой данных. Посмотрим на результат, который у нас получился.
Бэк-энд приложения написан на python c применением различных фреймворков для автоматизации машинного обучения, в том числе LightAutoML. Фронт-энд – на React.
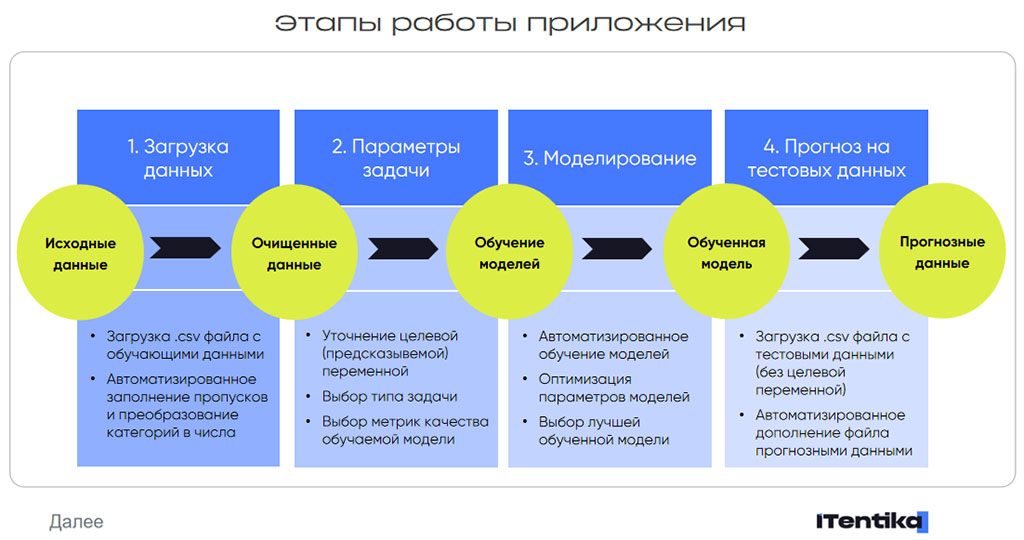
При входе в приложение появляется главный экран, который явно указывает на те этапы, которые необходимо пройти для построения модели машинного обучения. Эта «шпаргалка» нужна для пользователя решения, так как большинство работы будет происходить под капотом.

Следующий шаг позволяет загрузить обучающий набор данных в формате CSV. Этот формат крайне популярен при распространении данных, в этом формате можно выгрузить данные из различных учетных систем и т.п. Внутри решения набор данных преобразуется в привычный pandas DataFrame и дальнейшая работа идет с экземпляром этого класса.

На следующем шаге происходит параметризация задачи. Указывается название целевой переменной / таргета, тип решаемой задачи, а также метрика, которая будет оптимизирована в ходе обучения модели.
При этом, при наведении на каждое поле появляются подсказки, которые разъясняют пользователю назначение каждого поля, ведь мы говорим о неподготовленных пользователях.
Помимо указанных полей оставлены две «заглушки» для развития продукта в будущем: «Сфера деятельности» и «Вычислительная инфраструктура». Под сферой деятельности понимается доменная область, такая как, финансы, медицина и т.п. Поскольку у нашей компании есть опыт в разработке доменно специфичных решений, то этот опыт мы планируем внедрить в продукт. Например, пользователю в банке потребуется обучить модель для предсказания дефолта заемщика. Для этого пользователь укажет сферу деятельности «Финансы» и тип решаемой задачи, например, «Weight of Evidence».
Различные типы вычислительной инфраструктуры нужны для работы с большими данными. Если их (данных) много, то с локальной машины можно перейти на «Кластер».
Кроме того, на данном этапе, после указания таргета, происходит заполнение недостающих значений и нормализация данных. Например, LightAutoML не умеет обучать модели на данных, у которых встречаются пропуски в таргете (целевом столбце). Поэтому внутри решения удаляются строки, в которых значение целевой переменной пропущено.
Следующий экран демонстрирует процесс обучения, выбора и настройки модели машинного обучения. Для каждого типа задач (решение поддерживает регрессию, бинарную и мультиклассовую классификации) определены типы моделей, которые последовательно обучаются на тренировочном наборе данных. Также из тренировочного набора данных предварительно выделяется валидационный набор, на котором считаются метрики качества модели. Вывод этих метрик осуществляется на следующем экране.
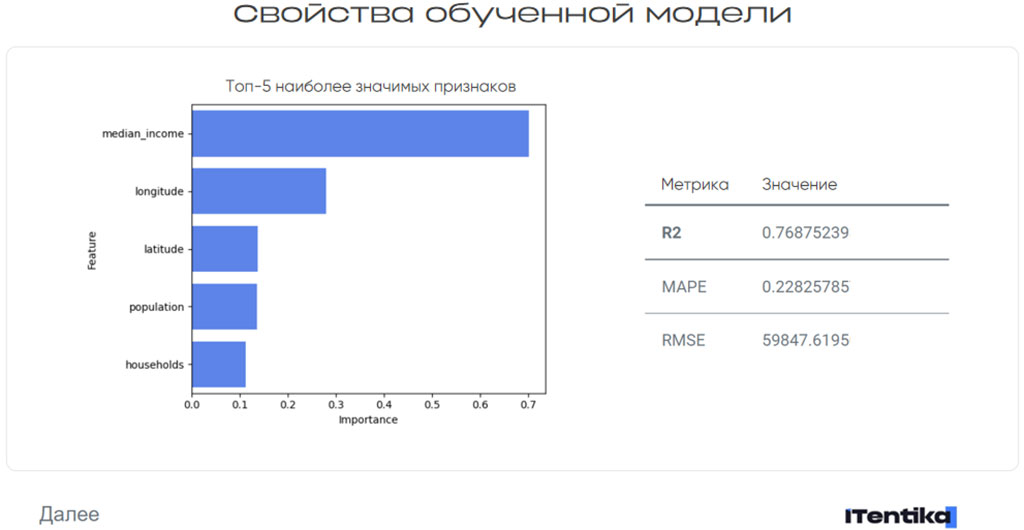
Помимо значения метрик выводятся рейтинг признаков, больше всего влияющих на поведение целевой переменной.
Далее, обученная модель сериализуется, сохраняется и становится доступной для получения прогнозов. На крайнем экране появляется возможность загрузить данные в формате CSV, на которых требуется сделать прогноз (данные без целевой переменной).

После загрузки данных они также обрабатываются и подготавливаются к передаче в модель, далее происходит вызов метода предсказания на новых данных. Предсказанные значения добавляются в виде нового столбца в загруженный набор и его можно скачать.
Таким образом, изучив за 30 минут в сети Интернет базовые идеи и несколько терминов из области машинного обучения, подготовив некоторый набор данных, пользователь может проверить гипотезу о наличии некоторых зависимостей внутри набора, после чего принять решение о целесообразности дальнейшего развития своей идеи. Привлечения исследователя данных в таком подходе, скорее всего не потребуется.
Выводы
Подавляющее большинство решений по автоматизации машинного обучения, доступных на рынке, – не дают возможности их использования без привлечения исследователя данных, так как порог входа в решения – довольно высокий.
Вместе с тем, рынок автоматизации машинного обучения – развивается и существуют несколько занятых сегментов. В первую очередь, это большие облачные решения, которые позволяют строить платформы промышленного уровня для крупного бизнеса. При этом, есть отечественные решения, которые способны заместить уходящий импорт: Sber, Yandex.
Во-вторых, есть готовые решения для подготовленных исследователей данных, которые позволяют им вести индивидуальную и групповую работу по разработке специализированных моделей под специфичные бизнес-задачи: Loginom, Dataiku, KNIME.
В-третьих, есть гипотетически не занятая ниша решений для автоматизации машинного обучения с минимальным порогом входа, которая не требует привлечения исследователей данных. Однако спрос на третий сегмент предстоит еще изучить.
